


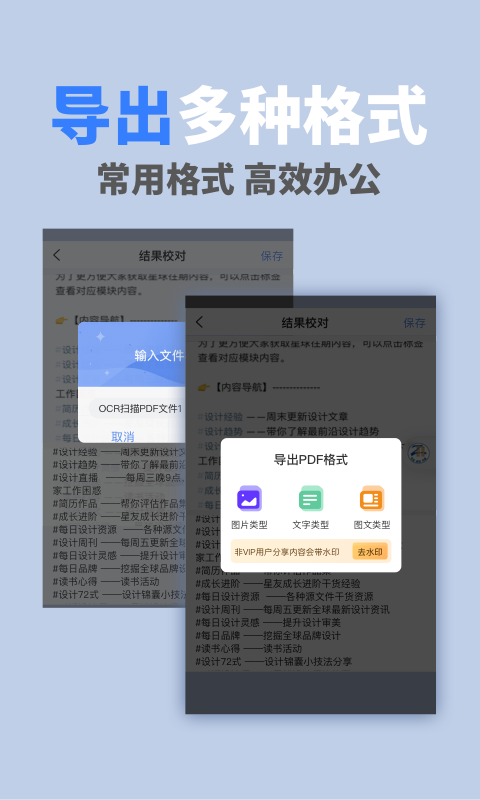
文字识别OCR扫描是一款高效、准确的文字识别软件,能够将图片、PDF文件中的文字快速提取并转换为可编辑的文本格式。
OCR(Optical Character Recognition,光学字符识别)技术是该软件的核心,它利用先进的图像处理算法和深度学习模型,对图像中的文字进行高精度识别。软件支持多种语言识别,并适用于各种场景下的文字提取需求。
1. 图片文字识别:支持从各类图片(如照片、截图、扫描件等)中提取文字,并将其转换为可编辑的文本。
2. PDF文字提取:能够解析PDF文件中的文字内容,支持对加密PDF的解密和识别。
3. 多语言识别:内置多种语言识别模型,包括但不限于中文、英文、日文、韩文等,满足不同语言环境下的文字识别需求。
4. 格式转换与编辑:识别后的文字可以保存为TXT、DOC、DOCX等多种格式,方便用户进行后续编辑和处理。
1. 用户界面:简洁明了的操作界面,提供一键识别、批量处理等功能按钮,方便用户快速上手。
2. 识别引擎:采用先进的OCR识别引擎,确保文字识别的准确性和高效性。
3. 语言包:支持多种语言识别模型的选择和切换,满足不同用户的语言需求。
4. 设置选项:提供识别精度、识别速度等参数的设置选项,允许用户根据实际需求进行调整。
1. 导入文件:点击软件界面上的“导入”按钮,选择需要识别的图片或PDF文件。
2. 选择语言:在软件设置中选择识别目标语言,确保识别结果的准确性。
3. 开始识别:点击“开始识别”按钮,软件将自动对导入的文件进行文字识别。
4. 保存文本:识别完成后,点击“保存”按钮,将识别结果保存为所需的文本格式。
文字识别OCR扫描软件在识别精度、识别速度、操作便捷性等方面均表现出色。其支持多种语言识别和格式转换功能,大大提升了用户的使用体验。同时,软件界面简洁明了,易于上手,即使是初次使用的用户也能快速掌握操作方法。在测试中,该软件对各类图片和PDF文件的识别效果均令人满意,是一款值得推荐的文字识别工具。
中医有方
评分:3文化:北国风云
评分:3
































































 4K剧下饭下载有哪些
4K剧下饭下载有哪些
 4K剧下饭正版
4K剧下饭正版
 繁花剧场
繁花剧场
 繁花剧场大全
繁花剧场大全
 繁花剧场app
繁花剧场app
 小夸搜剧免费版
小夸搜剧免费版
 pdf转换软件
pdf转换软件
 文件助手软件
文件助手软件



















